Tiago in Kitchen (Work in Progress)
This is a blog that covers my experience working on the final project of the 3 course specialization on coursera called Introduction to Robots with Webots. As I am first penning down this blog (As of April 7 2024), I completed the first 2 courses and I am almost through with the last course.
The final project in the last course requires me to implement a mobile manipulation solution which maps the environment and navigates the mobile Tiago Robot through the kitchen with obstacles that could be present anywhere (this is something the evaluator would do, as you can imagine; not going thru this can let someone cheat by simply providing some waypoints instead of actually solving the path planning problem).
The robot is supposed to plan and execute a trajectory from Point A to Point B and use the 7 DoF manipulator on it to pick and place certain objects using the force-feedback enabled gripper mounted at the end of the robot arm.
Prologue
A few months before I first put down this blog, I had an interview with a company that makes and deploys humanoid robots. After probing through my past projects in some technical depth and throwing technical questions at me, we moved on to the second part of the interview which was a simple question.
Imagine I have a robot arm mounted on a mobile robot and it needs to pick and place an object from Point A to B. How would I go about doing this? I was instructed to explain in the finest detail possible how I would accomplish the task in each subsystem. I was free to define the scenario in greater detail in any way I saw fit.
I thought about it for a moment, and first told him that I would use a behavior tree to architect the solution. Practically speaking, this THE architecture to solve such problems. I have used state machines in my garment automation project; although it wasn't quite a state machine, in the sense it didn't suffer from a lot of the drawbacks that people usually state for state machines, I could have imagined doing it much better with a behavior tree. Especially when it comes down to handling reactions to unusual but not totally unexpected situations you find out only when you actually deploy; the state machine becomes a mess of transitions in such cases, but in a behavior tree, this is simply a matter of adding new nodes that can either succeed or fail and which are fairly self contained i.e, you can add those nodes without any regard for the context in which they operate.
However, everything after this was downhill. My explanation was incoherent and lengthy (although he did say to go deep all the way). I proposed solutions that were based off of past experiences, especially when it comes to anything that is perception-related (I consider this my weakest link), even if they were not the best approach.
- I proposed using an RGB camera to detect objects in the image using a CNN trained to detect specific objects and then use a stereo camera to compute the distance of said objects from the robot, and using knowledge of the objects' dimensions and the camera's intrinsics and extrinsics, drawing a circle on an obstacle grid which is padded by the robot's size.
- This is called a Configuration space and this is the exact approach we used in the NASA-SRC where I did precisely this, I didn't work on the perception, but I did take the objects' information and create the C-space.
- I then explained I would use A* to make the robot plan a path to the goal, assuming its a static environment.
- I would then use the waypoints to compute a trajectory using a cubic polynomial trajectory and finally feed wheel joint velocities to the differential drive robot to track the trajectory. There would be PID controllers at that joint level to minimize the wheels' velocity error.
It was something like this (I am jotting this from memory) :

Ofcourse what I was missing out was how these tasks would translate into the behavior tree. I either didn't think to do that or was simply thought it wasn't important / was trivial to do so. Its wasn't. Moving on....
Once the robot reaches the table or wherever the object is, I used what I learnt when I took the robot manipulation course. I would use the Point Cloud Library to detect the largest plane in the point cloud (which I get from the same depth camera) using something called Plane Model Segmentation. I explained to him straightaway that I didn't know how this works, but I have used this functionality before to do exactly this.
- Assuming that object is the only one on the table (this is a very simplistic and unlikely assumption, but by this point I was constructing the scenario to fit my solution), I would use the DexNet-2 network to compute the best antipodal grasp for the object.
- I left out the details of how to feed the point cloud. It can't be fed directly into DexNet-2 and I knew it. But I left this out for the sake of time.
- I would then query the robot gripper to move to that grasp pose.
- In order to plan this path, I would use RRT to plan the path using random robot joint configurations, which allows me to collision-check with the environment (again, I am limited by the point cloud I get from the cameras to get the representation of the environment I have but I failed to acknowledge this). He asked me why I was using RRT instead of A*. My response was the usual - in this particular case, we don't care about shortest path, we need a safe path and using A* would be an unnecessary computational nightmare. Along with a 3D space, we also have the joint space (admissible joint configurations; joint limits and collision checking) to consider in the path exploration.
- Assuming I get a collision-free path, use the same trajectory generator I used for navigation to compute joint velocities.
- Again, these joints would have PID controllers to drive them to their respective setpoints.
This looks something like this:
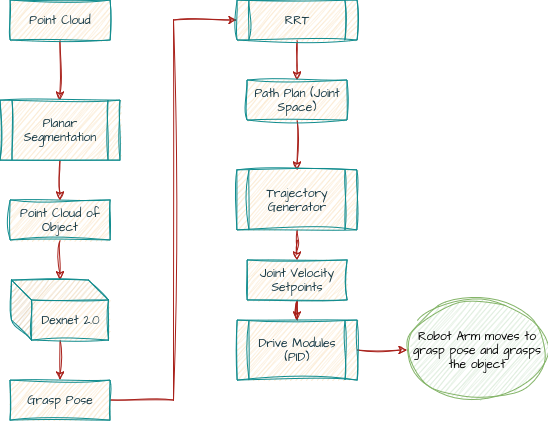
The closing and placing wouldn't demonstrate any additional thought process / skills, so he and I agreed to stop discussing the solution at that point. At that point, the time was over for the interview. I was yet to cover the coding round, but he said it was alright (I don't think it was) and the interview was over. I knew right then and there that it had been a disaster. I admit the solution looks a little better with all those diagrams above, but during the interview, I am pretty sure my explanation was all over the place and he walked away from the interview without understanding the structure of my solution.
Motivation
My motivations to pursue this course were two-fold:
- To be adeuqately able to tackle such problems in the future.
- My work experience in the food service industry which has given me enough context and understanding of how such problems present themselves.
Motivation#1
This interview was exciting. Yes, it was a simple scenario, but I know that currently the strategy for robotics interviews by most companies is to actually put forth the closest scenario I would encounter as the problems I would be working on there instead of throwing a LeetCode binary tree problem. This was an exciting problem to solve, and one that presents the current state of what NEEDS to be solved.
There are so many things that I could benefit from - both in breadth and depth to come up with the right solutions for such problems. But I wanted to make good use of my time. I feel I already have the minimum depth - both in software and in robotics to work on a high level solution to such problems with the low level components being fairly simple.
That's what drew me to this course. It presents a simpler version of the real environment in which I would have to solve the exact same problem, but at the end of it, I would gain hands-on experience implementing a complete end-to-end solution and then I work my way up from there to work on more complex scenarios and go into greater depth on techniques for said scenarios.
For instance, in the course, a GPS and a magnetometer are simulated to provide the robot's pose which are accurate and their precision is in the order of millimeters and milliradians respectively. This is ridiculous but allows me to ignore the localization problem. When I do need to make the problem more complex by using the actual sensors one would use to solve the problem in real-life, I could replace those magic sensors with a SLAM module that takes in the realistic sensor readings and produces the exact same thing I need, a C-space and the robot's pose.
Motivation#2
I have worked 2 different kinds of part / full time blue collar jobs. I once worked in my campus dining hall. The dining services were outsourced to a major dining services provider. I I worked part-time in various capacities; I would initially for the most part serve food from the containers as it was COVID and we didn't want several students using the same utensils to serve themselves and spread COVID like wildfire.
I also worked as a dishwasher loading up dishes into the giant dishwasher, I would sometimes sign up for just keeping the hall clean, and sometimes with cutting vegetables. And ofcourse closing is one of the crucial components of food services related jobs. This job was very well-defined and well managed, I barely if ever had any complaints.
I also worked in a deli cum convenience store. It was located close to a university, so the weekend would be bustling with students who have had their parties. This was a small business and due to the nature of small businesses, they cannot be consistent about everything. Every decision is a day-to-day decision or week-to-week decision, such as taking out deli meats, the hours for the store, how much stock to procure for a particular item, etc. Over the years, they did arrive at some form of structure and key instructions to run the store, but there was still a lot of exceptions made all the time.
This was a hard job for me. I am not going to go into details, but it was unpleasant to work here. But the pro is since I managed the store all on my own on some days of the week, I learnt a lot of things here that come with taking responsibility. As opposed to that dining hall, where I served as a tiny module serving a small well-defined role in a large context; here I was given the opportunity to make several moving pieces of the store work together and budget it within the time ans resources available to me. I sucked at this initially, but I think I got better at it with time.
Contrasting these 2 businesses, although its true that the larger dining service could also accrue more losses, their business is often too geographically diversified, a failure in one place won't affect the other. Its clear the big business has an advantage in almost every aspect, such as:
- Keep employees on a schedule regardless of how the business is going.
- Not worry about food wastage. Infact, they often throw this food out and deny them to the workers who would be more than happy to take it home. If the logic behind this is to discourage bootlegging, I am sure there can be better ways, albeit maybe not convenient or cost-effective for them.
- Better equipment in every aspect and very often equipment for an essential functionality that small businesses can't afford. Ease of use, efficiency, safety, maintenance, better quality output, ease of being compliant with the FSIS, etc.
- Better space. Larger space. During the weekend, we would have a storm of students lining up in the store area. They improvised by having one of the workers discipline the line, and very often it was me. Nonetheless, this was an arduous and unpleasant task, where a 100 instructions would have to be dished out to the less-than-sober students (I am not criticizing them, they were actually remarkably well behaved for someone who was drunk and were often fun to talk to), but the instruction-dishing was unpleasant and would very easily be solved with a larger space and a set of equipment / devices to avoid this part of the job entirely.
- Although the above is specific to this store, I am sure there are similar problems faced with other small businesses where small space presents a challenge. For instance, when I opened on Sunday and had to clean up the entire store from the mess made in the weekend, I had to do so, with customers walking in all the time. This was a significantly lesser problem when I cleaned up in the large dining hall I worked at.
- Simply put, harder work for the employees. This leads back the earlier points I have made about equipment and space. But very often, the employers of small businesses cannot afford to pay what large businesses pay for less harder work.
- Trained staff. You have college graduates trained in specific details about food and equipment handling who often manage a dining hall /service or components of it. Or at the very least, experienced people that these large businesses can afford to hire.
I will go into greater detail when I formulate the larger and the less abstract problem statements for small businesses as well as present larger data-points that reflect common themes (this informs whether a specific problem is worth solving). But suffice to say, the fact that this course focuses on robots performing tasks in a kitchen environment would definitely give me some of the skills and approaches to solve such problems. My hunch here is that the increasing flexibility and affordability in robotics aided by AI and other advances can do away with most disadvantages small businesses face.
At this point someone would ask, why should small businesses even exist? Larger businesses often make it harder to adapt to the needs of a local scenario, small businesses have all the room to experiment as much as they can and avoid the redtape. Ever been to a subway and asked them to customize something and received either a frown or that they are either unauthorized to do something or unable to figure out how to go about it? I have had several instances where I was able to do so with complete authority and figure out a way by myself. Or it's simply the fact that a local small business is beneficial and connected to the community and are not run like assembly lines.
What is accomplished in the course so far?
Before I discuss the problem at hand, I will explain what I accomplished in these 3 courses and setup the context for the problem statement. These courses were very well structured and the Webots simulator is very easy to interface using its simple yet powerful API.
Course 1 : Basic Robot Behaviors & Odometry
- Got acquainted with webots, including how to setup world, lights, the physics, robots, devices. etc. and how to interface with them.
- Implemented a reactive controller that would minimize the translation and rotational errors of the robot with respect to a line that it follows. A lot of if-else conditions were used to accomplish this.
Course 2 : Mapping & Navigation
- I cleaned up the reactive controller and made it follow a set of waypoints circumnavigating a table in the kitchen, and passing through narrow corridors. In order to do so, I had to tune the controller to execute smooth trajectories. I noticed that while turning the castors would be displaced by some angle. And after the turn, when commanding the robot to move straight, it would go off-path until the castors straightened out. I resolved this by executing radial turns instead of turn-in-place to prevent the castors from reaching an extreme orientation.

- I then mapped out the environment by including a laser range finder in the robot and using the distance readings to first convert them to the world frame from robot frame. This was accomplished by using a simulated GPS and Compass which were ridiculously precise and gave the robot's pose in the world frame.
- I mapped the environment using an occupancy grid, mapping from metres to pixels. Every time a distance reading was received, I increased the probability of the pixel being occupied by a certain value.
- I then implemented Bresenham's line algorithm to efficiently reduce the probability of all pixels in the line of sight of being occupied. I had to reduce this by a lower factor as the odometry errors were still significant (they were gaussian but not accumulative in nature, unlike, say, an encoder) and would reduce the probability for the wrong pixels.
- I then applied convolution to pad all obstacle regions by the size of the robot in the pixel-space. I then applied a threshold to generate the C-space (0s and 1s). I had to optimize the kernel size and this threshold to leave a pixel wide space at the narrow corridor (course requirement) and that the robot follows this narrow pixel space.
Below is the result :
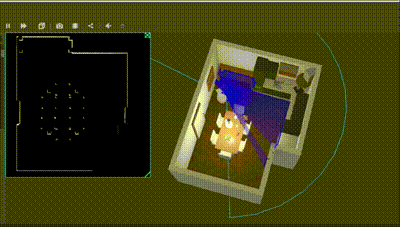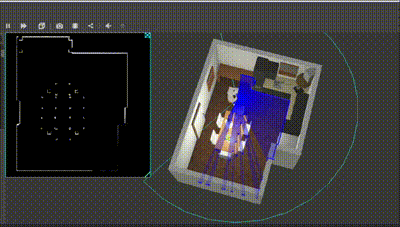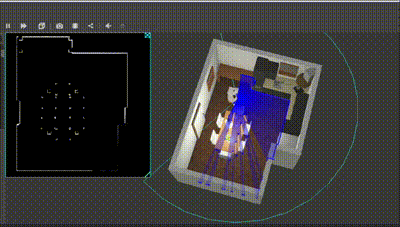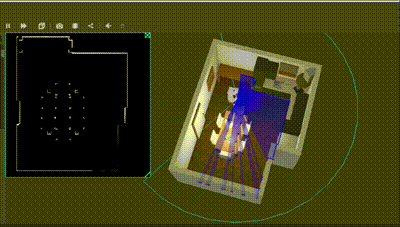

Course 3 : Path Planning & Task Execution
In this part of the course, the following were accomplished:
- Various path planning algorithms were written and tested like BFS, Dijkstra, A*, RRT, RRT*.
- The behavior tree library py_trees was used to implement behaviors to map the environment, plan a path from the robot's position to points of interest in the kitchen (like the sink) and successfully drive the robot to the goal.
- Behaviors to control the robot arm's joints and gripper were implemented to simply command the joints to pick up an object (not in task space).
- A behavior was implemented to first detect an object in the RGB image using the pose recognition module in Webots and then transform that object's position from camera frame to the body frame using Forward kinematics (using DH parameters).
- The course ends with a project where everything is put together and will be discussed in the problem statement.
Below is the robot planning and navigating to the lower left corner and the sink. The behavior tree checks for the map; if unavailable, it circumnavigates the table twice and stores the C-space; in this case it was available. Check the terminal in the video to see the behavior tree updates.